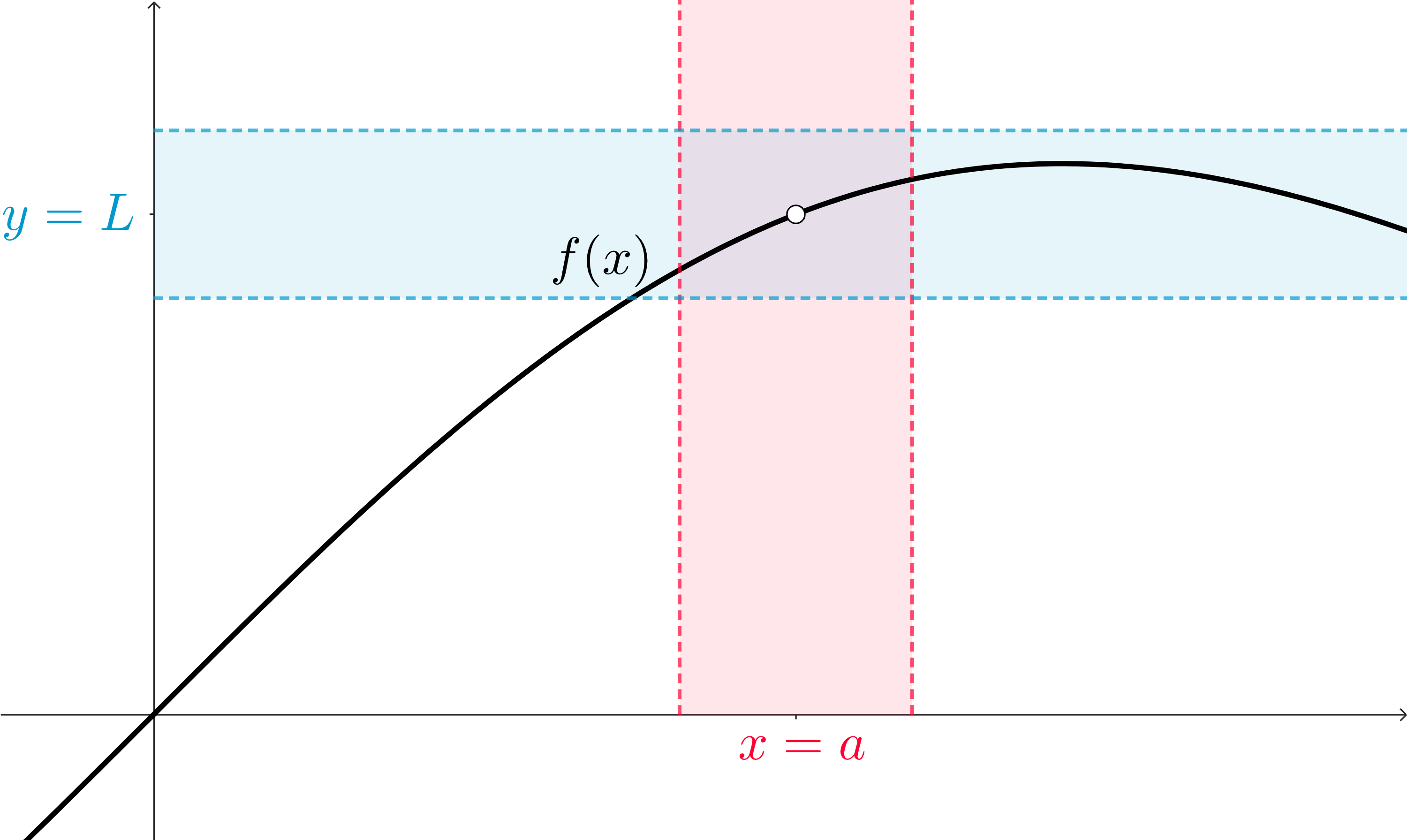We’re going to start this textbook by stating a definition. This is a common practice in math classes: we need to agree upon a common definition of the mathematical objects and adjectives we are thinking about. We will state a lot of definitions in this textbook.
What I hope we will do, though, is motivate these definitions. We want to arrive at a point where it makes sense to give a name to this phenomena or object that we’re thinking of. Or maybe we arrive at a point where the specifics of the definition don’t just come down to us out of nowhere, but feel like reasonable and obvious things to consider.
We’re going to try to think how we might define “close”-ness as a property, but, more importantly, we’re going to try to realize the struggle of creating definitions in a mathematical context. We want our definition to be meaningful, precise, and useful, and those are hard goals to reach! Coming to some agreement on this is a particularly tricky task.
Let’s think about how close two things would have to be in order to satisfy everyone’s definition of “close.” Pick two objects that you think everyone would agree are “close,” if by “everyone” we meant:
All of the people in the building you are in right now.
Let’s put ourselves into the context of functions and numbers. Consider the linear function \(y=4x-1\text{.}\) Our goal is to find some \(x\)-values that, when we put them into our function, give us \(y\)-value outputs that are “close” to the number 2. You get to define what close means.
Pick five more, different, numbers that are “close” to 2 in your definition of “close.” For each one, find the \(x\)-values that give you those \(y\)-values.
To wrap this up, think about your points that you have: you have a list of \(x\)-coordinates that are clustered around \(x=\frac{3}{4}\) where, when you evaluate \(y=4x-1\) at those \(x\)-values, you get \(y\)-values that are “close” to 2. Great!
Do you think others will agree? Or do you think that other people might look at your list of \(y\)-values and decide that some of them aren’t close to 2?
Do you think you would agree with other peoples’ lists? Or you do think that you might look at other peoples’ lists of \(y\)-values and decide that some of them aren’t close to 2?
The balance that we need to find, as we discovered in Activity 1.1.1, is about being able to leave room for those with a very strict idea of what “close” might be. We will want to think of an idea kind of like “infinite closeness,” but we’re not going to frame it this way: we’re going to think about a function’s output being so close to some specific number that literally everyone can agree. It is so close that it is within every possible definition of closeness.
The general idea is that we want to think about the behavior of a function at inputs that are near some specific input. Is there a trend with the outputs? Are they all centered around a specific value or do they differ wildly?
For the function \(f(x)\) defined at all \(x\)-xalues around \(a\) (except maybe at \(x=a\) itself), we say that the limit of \(f(x)\) as \(x\) approaches \(a\) is \(L\) if \(f(x)\) is arbitrarily close to the single, real number \(L\) whenever \(x\) is sufficiently close to, but not equal to, \(a\text{.}\) We write this as:
\begin{equation*}
\lim_{x\to a} f(x) = L
\end{equation*}
or sometimes we write \(f(x) \to L\) when \(x\to a\text{.}\)
There are two types of “close” in this definition: “arbitrarily close” and “sufficiently close.” One of these is in references to \(x\)-values being close to a number and the other is in reference to function outputs being close to a specific number.
We are concerned with the behavior of a function around, but not at, a specific \(x\)-value: \(x=a\text{.}\) We don’t really care about what the function is doing at that input (if anything at all), and we already have words to describe that kind of behavior!
When we talk about \(x\)-values that are near \(a\text{,}\) that might reference \(x\)-values that are a bit bigger than \(a\) or \(x\)-values that are a bit smaller than \(a\text{.}\) We can be more specific by simply changing this definition to focus on only one “side” individually.
We can go back to Activity 1.1.1 and think about how we chose \(x\)-values that were larger than \(\frac{3}{4}\) and smaller than \(\frac{3}{4}\text{.}\) Let’s define these ideas a bit more formally!
For the function \(f(x)\) defined at all \(x\)-xalues around and less than \(a\text{,}\) we say that the left-sided limit of \(f(x)\) as \(x\) approaches \(a\) is \(L\) if \(f(x)\) is arbitrarily close to the single, real number \(L\) whenever \(x\) is sufficiently close to, but less than, \(a\text{.}\) We write this as:
\begin{equation*}
\lim_{x\to a^-} f(x) = L
\end{equation*}
or sometimes we write \(f(x) \to L\) when \(x\to a^-\text{.}\)
For the function \(f(x)\) defined at all \(x\)-xalues around and greater than \(a\text{,}\) we say that the right-sided limit of \(f(x)\) as \(x\) approaches \(a\) is \(L\) if \(f(x)\) is arbitrarily close to the single, real number \(L\) whenever \(x\) is sufficiently close to, but greater than, \(a\text{.}\) We write this as:
\begin{equation*}
\lim_{x\to a^+} f(x) = L
\end{equation*}
or sometimes we write \(f(x) \to L\) when \(x\to a^+\text{.}\)
Introduce how we will build our results throughout the course of this text. We want to discover these results as things that are required for us to talk about (and do) calculus together, and hopefully we can motivate each one beforehand.
For a function \(f(x)\text{,}\) if both \(\displaystyle\lim_{x\to a^-} f(x) \neq \lim_{x\to a^+} f(x)\text{,}\) then we say that \(\displaystyle\lim_{x\to a} f(x)\) does not exist.
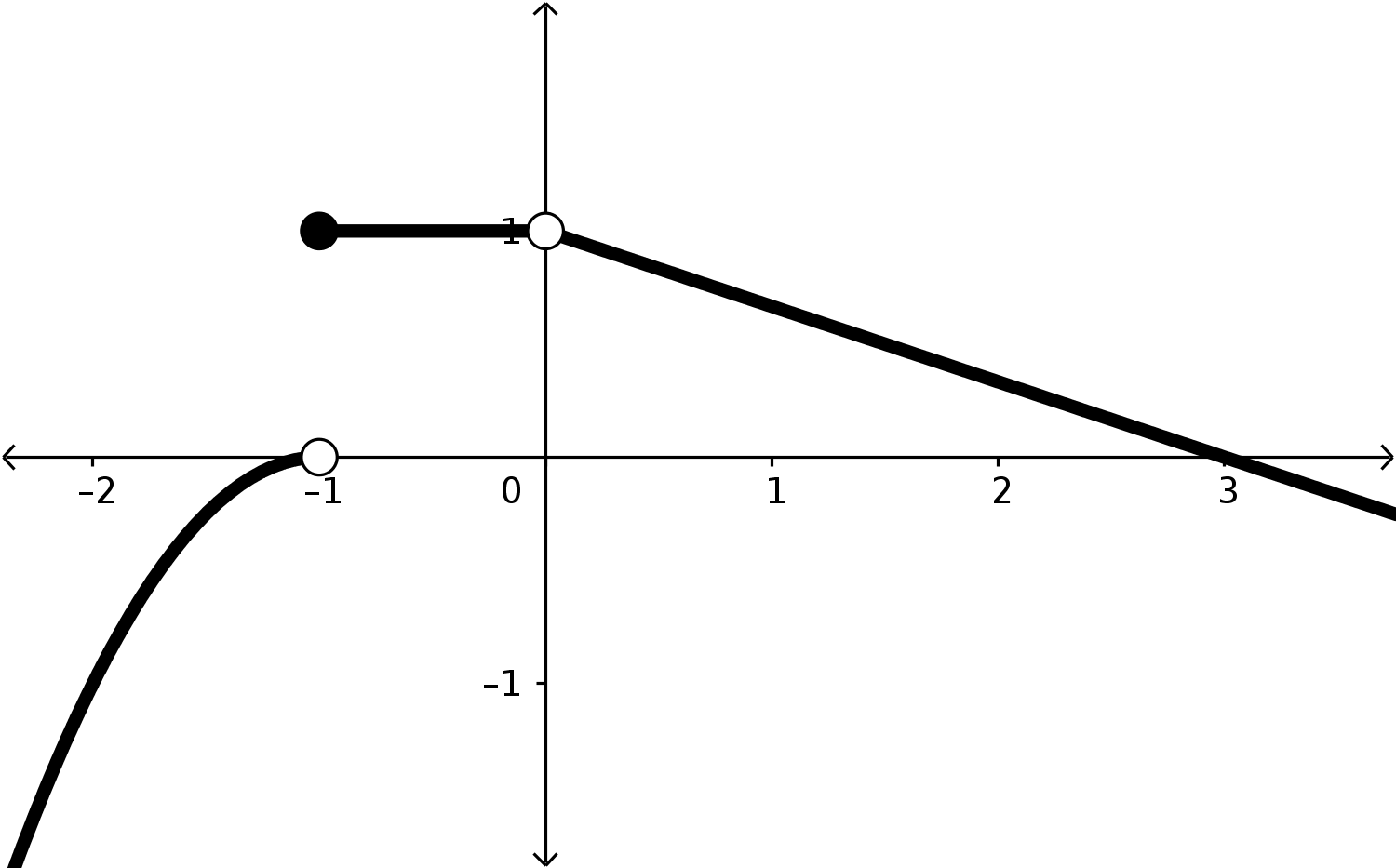
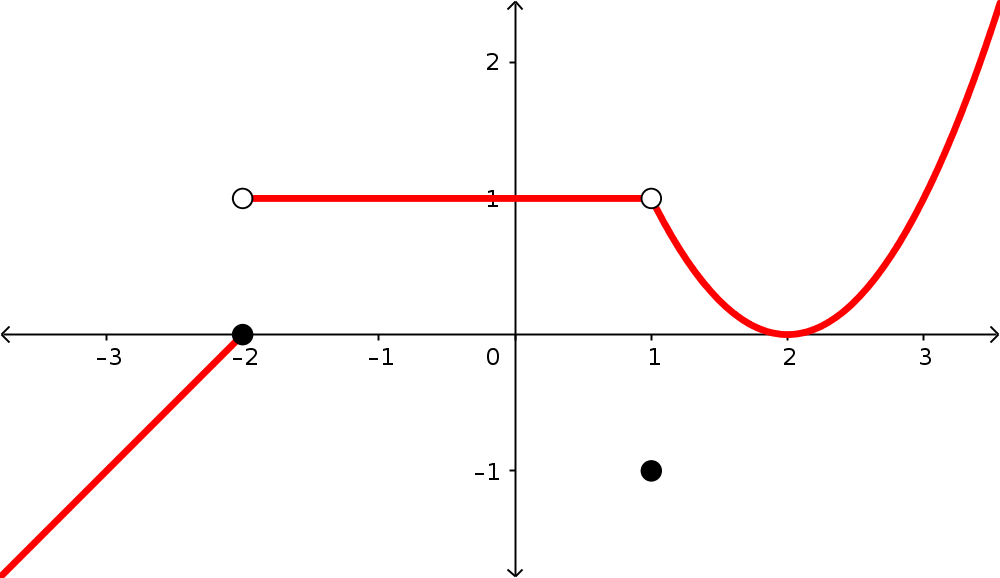
We will eventually get really good at thinking about limits and using them, but for now we just want to get familiar with them. Let’s approximate these values that our function is near by looking at some pictures of graphs and some tables of function outputs.
For each of the following graphs of functions, approximate the limit in question. When you do so, approximate the values of the relevant one-sided limits as well.
What extra details would you like to see to increase the confidence in your estimations? Are there changes we could make to the way these functions are represented that would make these approximations better or easier to make?
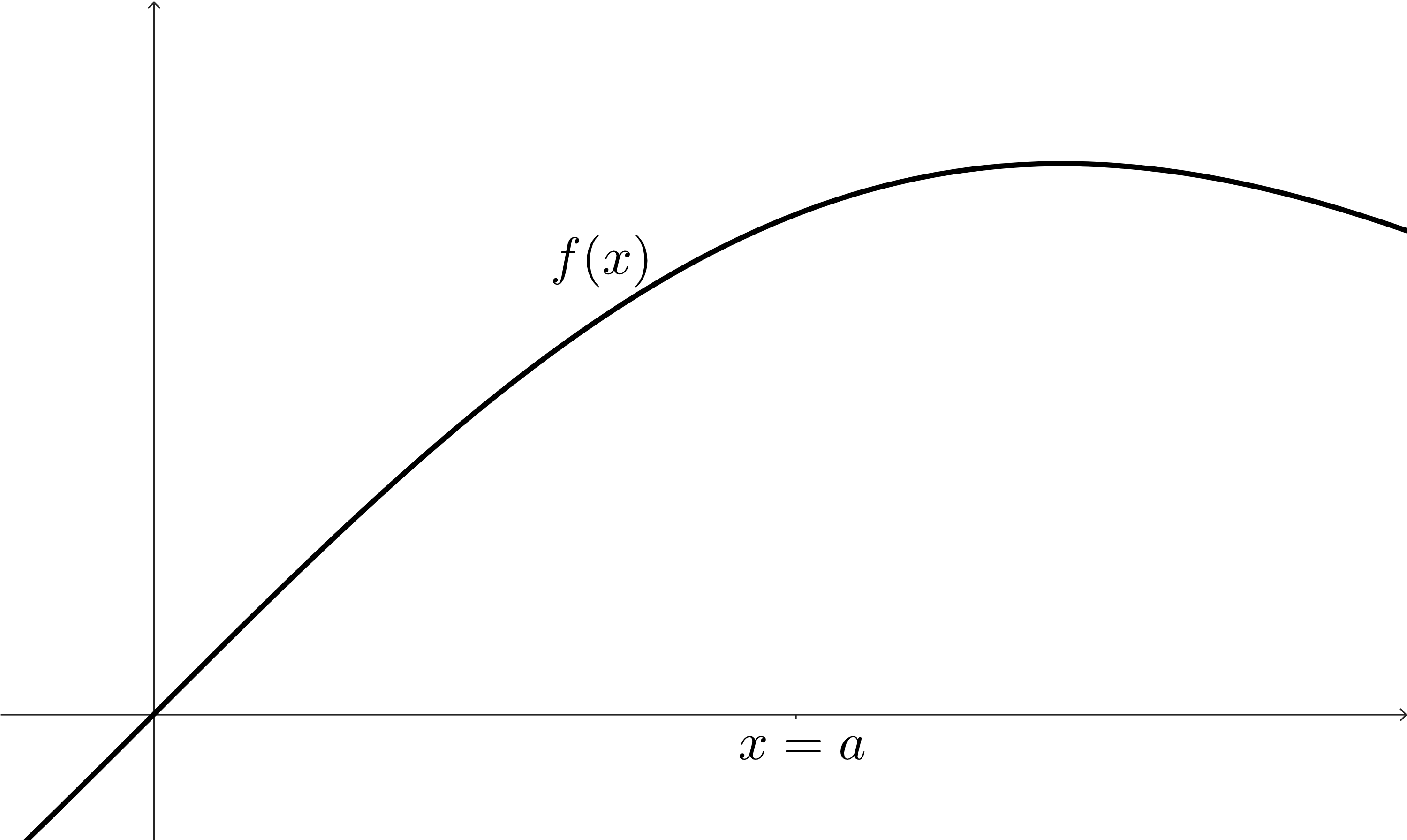
It can be hard to focus on the aspects of a graph that we really care about for the purpose of a limit. Let’s build a small strategy to help us think about what we’re looking at. We’ll start by just considering some function, \(f(x)\text{.}\) Using our definition of the Limit of a Function as a guide, we’ll make sure that it’s defined around some \(x\)-value, \(x=a\text{.}\)
We can see that we might as well remove any point at \(x=a\) from our graph: we are only concerned with the behavior around that \(x\)-value instead of the function’s behavior at it.
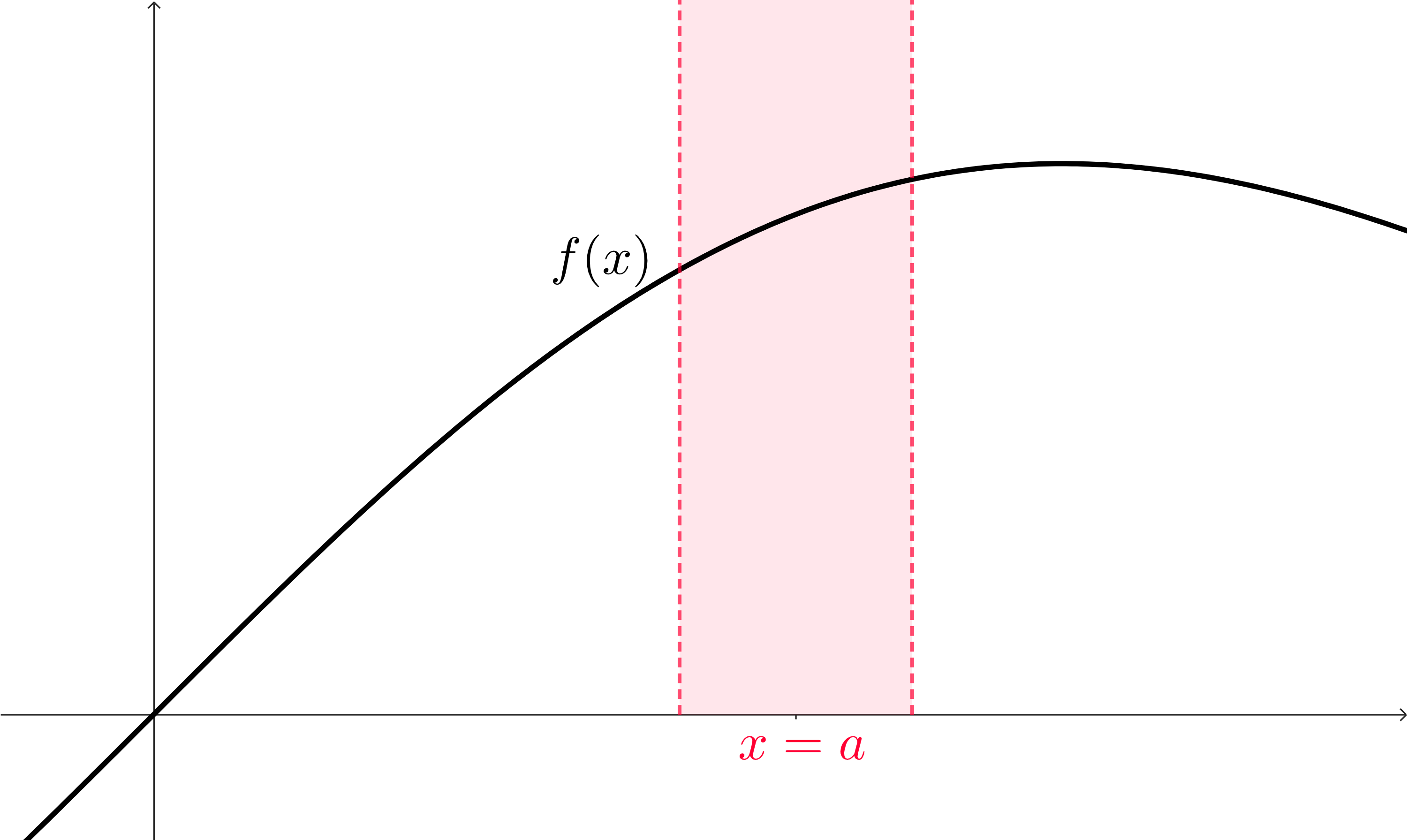
And now our focus can turn to the function outputs. For the \(x\)-values in this interval of inputs that we’ve constructed, is there some common real number that the corresponding function outputs are close to? We can visualize some interval of \(y\)-values. We’ll think of this as a target: we want to build an interval of \(y\)-values that all of the function outputs from this interval of \(x\)-values land in.
This is a pretty wide range of \(y\)-values, but we can see that the graph of the function (when we limit to just the interval of \(x\)-values selected) produces function outputs that exist only in that interval. We don’t fill the interval, but that’s fine!
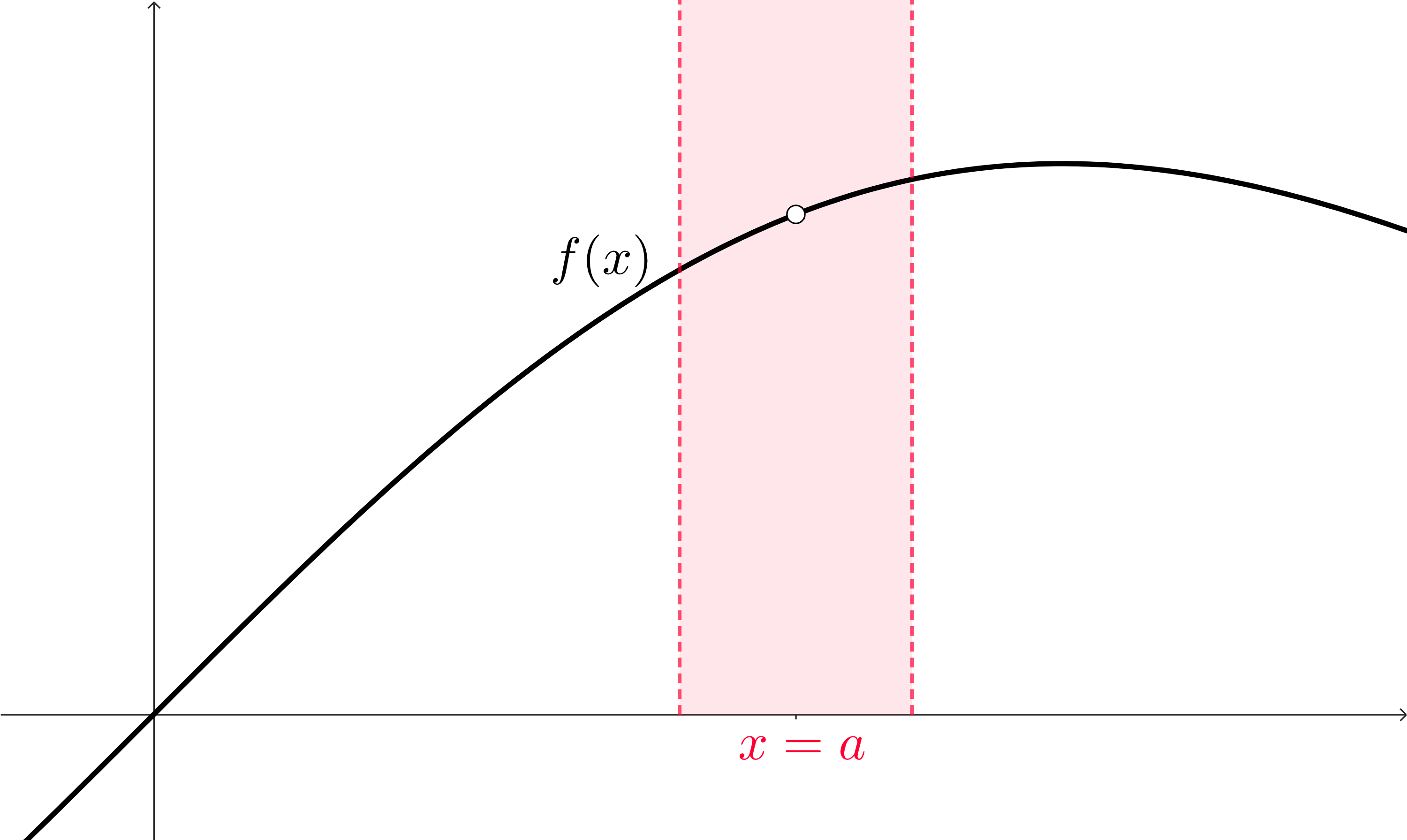
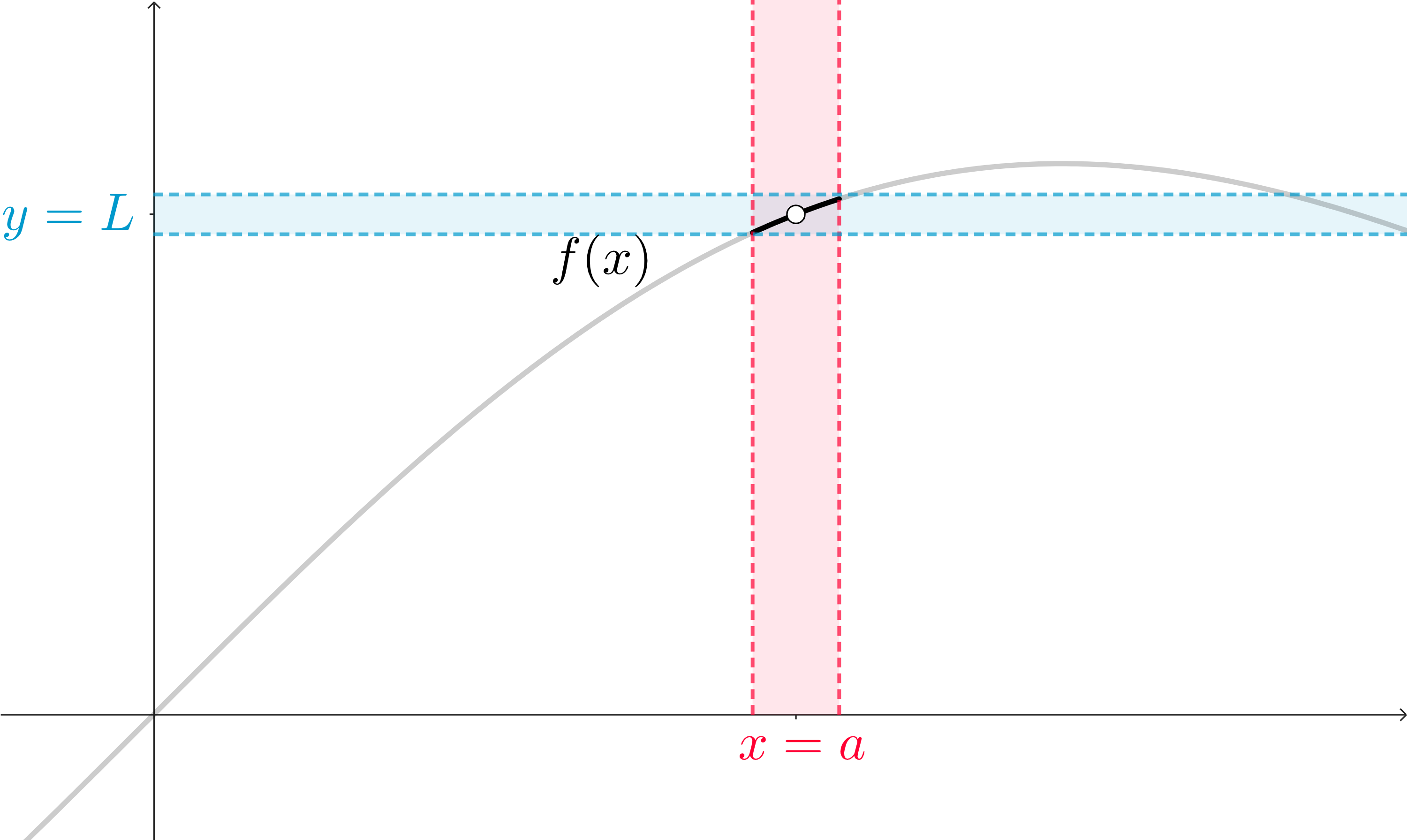
What we really care about, though, is if these function outputs are all close to the same, single, real number. What we can do is look at a more strict idea of “closeness” in the \(y\)-interval by shrinking it. In order for us to produce function outputs that are in this new, smaller, interval, we’ll need to correspondingly shrink our interval of inputs to more closely surround \(x=a\text{.}\)
In this visualization, we’ve also tried to focus on just the portion of our function that exists in this little intersection of intervals: we want to know what these functions values are close to, or more specifically if they are all close to the same thing. So we can de-emphasize the rest of our function!
All we’re doing is working on a strategy to focus on the parts of this graph that matter: only the parts of the curve that are surrounding \(x=a\) (but not that actual point specifically). From there, we just want to know what the function outputs are clustered around, if anything.
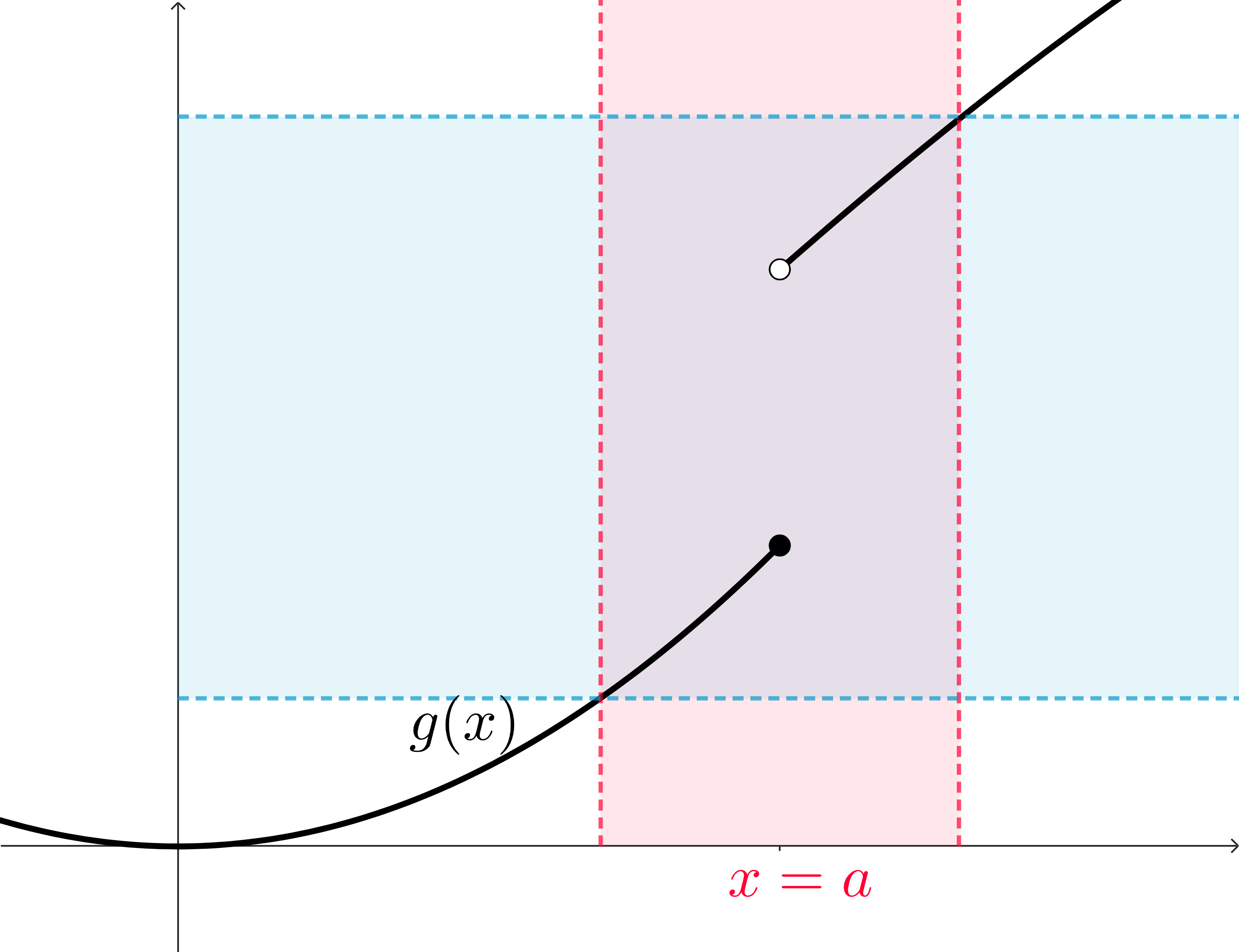
Let’s look at this same kind of visualization for a limit that does not exist: we’re going to think about the case where the one-sided limits don’t match. We’ll start a little further on in this visualization process: we have a function, and we can visualize an interval of \(x\)-values whose function outputs land inside a target interval of \(y\)-values.
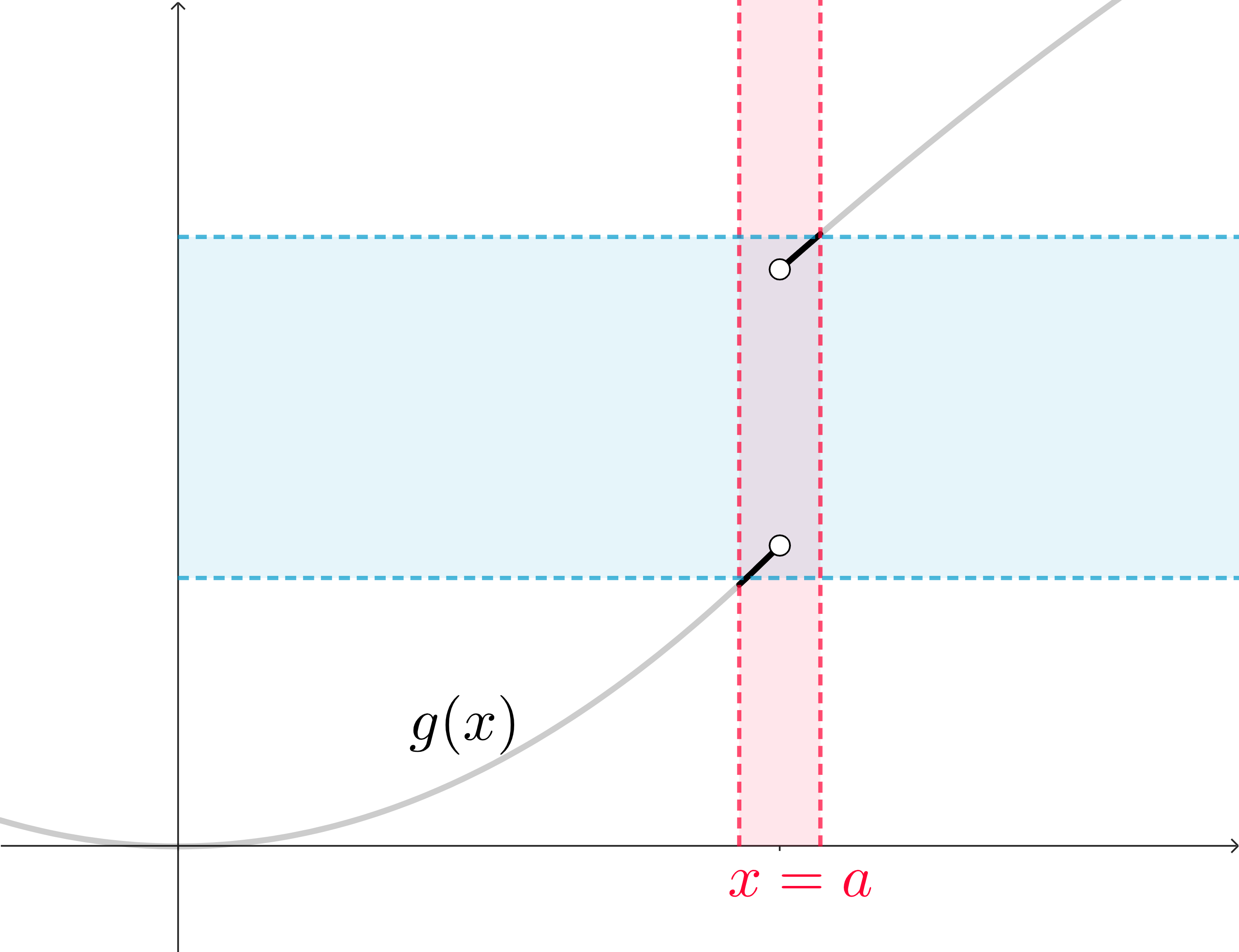
We can see the problem: that vertical space between the function on the left of \(x=a\) and the where the function values are on the right of \(x=a\) will make it so that horizontal bar cannot get much smaller. We can disregard the point at \(x=a\) as well as the function outside of the interval, but once try to shrink the target interval of \(y\)-values, but we’ll see the problem.
These function outputs are spread apart! They are not close to a single value. Instead, they’re close to two! The function is close to a value on the left side, and then the function is close to a larger value on the right side.
\begin{equation*}
\lim_{x\to a^-} g(x) \neq \lim_{x\to a^+} g(x) \text{ and so } \lim_{x\to a} g(x) \text{ does not exist}\text{.}
\end{equation*}
Now let’s think about how we can approximate (and learn more about) limits using when we just think about the actual values of a function’s inputs and corresponding outputs.
For each of the following tables of function values, approximate the limit in question. When you do so, approximate the values of the relevant one-sided limits as well.
What extra details would you like to see to increase the confidence in your estimations? Are there changes we could make to the way these functions are represented that would make these approximations better or easier to make?
Overall, there’s a common theme here: in either representation (graphically or numerically), we’re making a best guess at the behavior of the function values around a point. We have limited information in these estimations, and so we’re doing the best we can: in graphs, we’re trying our best to make sense of the lack of precision in the scales of our visual, and in the numerical tables we are only given a limited number of points to think about. In both cases, we are hoping to see more information to add more confidence to these estimations.
We want to make the jump from estimating these limits to evaluating them, and for that to happen, we’ll need to add more information and more precision about the behavior of our function.
Say we know that \(\displaystyle\lim_{x\to3^-} f(x)=2\) and \(\displaystyle\lim_{x\to 3^+}f(x)=2\text{.}\) What do we know (specifically or in general, if anything) about each of the following?
For some function \(g(x)\text{,}\)\(\displaystyle\lim_{x\to 4^-} g(x) = -\dfrac{3}{2}\) and \(\displaystyle\lim_{x\to 4^+}g(x) = \dfrac{4}{7}\text{.}\)
This is not possible, since for \(\displaystyle \lim_{t\to\alpha} \ell(t) = 2\) we would need \(\displaystyle \lim_{t\to \alpha^+} \ell(t) = 2\) and \(\displaystyle \lim_{t\to \alpha^-} \ell(t) = 2\text{.}\)
For some function \(r(\theta)\text{,}\)\(\displaystyle\lim_{\theta\to 0}r(\theta)\) does not exist, \(\displaystyle\lim_{\theta\to 0^-}r(\theta)=\pi\text{,}\) and \(\displaystyle\lim_{\theta\to 0^+}r(\theta)=-\frac{\pi}{2}\text{.}\)
Requirements:\(f(6)=0\text{,}\)\(\displaystyle\lim_{x\to6 } f(x)=-2\text{,}\)\(\displaystyle\lim_{x\to-2^-}f(x)=1\text{,}\) and \(\displaystyle\lim_{x\to -2} f(x)\) does not exist.
Requirements:\(\displaystyle\lim_{\omega\to 0 } \rho(\omega)=8\text{,}\)\(\displaystyle\lim_{\omega\to2 }\rho(\omega)=-2\text{,}\) and \(\rho(2)\) does not exist.